HTTP的URL编码
文章目录
背景
案例 1
向 Flask 接口发送 GET 请求,发现获取到查询参数中+变为了空格。
|
|
案例 2
向 Flask 接口发送 POST 请求,发现获取到数据中+变为了空格。
|
|
为什么
Flask 做了啥?
- Flask 通过
request.args和request.form获取请求参数,最终都会经过一个_url_decode_impl函数对其进行解码
|
|
- 其中
url_unquote_plus函数是先对键值中的+替换为空格,再按%分组解码。
|
|
所以 Flask 框架下认为拿到的请求数据是已经被 URL 编码的数据,自动进行了解码工作。而这解码工作中就包含了+的替换以及百分号编码。
参数中1+2中的+被认为是空格的编码,解析时就把+转换回空格了,变成1 2。
不止 Flask 框架,其他语言的 Web 框架也有相似的操作,比如 Go 的标准库net/url。
为什么获取到的参数会需要解码呢?解码规则又有哪些呢?
什么是 URL 编码?
也叫百分号编码,由百分比字符%后跟替换字符的 US-ASCII 的十六进制表示。
在RFC3986标准中有明确定义:URL 由一字母、数字和一些特殊字符组成,特殊字符用于分隔或标识。
|
|
| 结构 | 说明 | 语法 |
|---|---|---|
| schema | 协议 | ALPHA *( ALPHA / DIGIT / “+” / “-” / “.” ) |
| authority | 权限 | [ userinfo “@” ] host [ “:” port ] |
| path | 路径,类似文件系统的层次结构 | _( “/” _(unreserved / pct-encoded / sub-delims / “:” / “@”) ) |
| query | 查询字符串,检索资源 | *( pchar / “/” / “?” ) |
| fragment | 片段,指向资源特定部分 | *( pchar / “/” / “?” ) |
为了确保 URL 能被正确解析避免歧义,其他字符或不用于其分隔或标识目的的特殊字符需要被编码,转换成在 URL 中没有语法意义的表示,即 URL 编码。
如:http://example.com/what?.jpg经过编码转义为:http://example.com/what%3F.jpg,确保?不会被认为是路径和查询的分隔符,被错误解析。
标准里也指出了 URL 中的几种字符:
- 保留字符:用于分隔目的的字符,当不用作分隔时需要编码
|
|
- 未保留字符:允许但没有保留用途的,不需要编码
|
|
- 不安全字符:容易引发歧义的字符,始终需要编码
| — | — | | 空格 | 当 URL 被转录、排版、接受文字处理程序的处理时,重要的空格可能会消失,并且可能会引入不重要的空格 | | % | 用于对其他字符进行编码 | | # | 在 www 和其他系统中用于将 URL 与片段/锚定分隔开可能跟随它的标识符 | | " | 在某些系统中用于分隔 URL | | <> | 被用作自由文本中 URL 的分隔符 | | {}|\^[]`~ | 已知网关和其他传输代理有时会修改这些字符 |
可以看到空格作为“不安全的字符”,是需要百分比编码的,空格的十六进制表示为 20,则空格应该编码为%20,为什么会有编码为+的情况呢?
URL 不同部分编码不同
URL 不同部分的保留字符不同,如字符+在路径中是不用编码的,但在查询字符串中是保留字符,需要被编码:
|
|
路径中a+b的+即被认为是加号本身,解码时不会被转义,而参数中1+2的+则被认为是空格的转义,将解码为1 2。
如果需要在参数中传递正确加号本身,则需要先将+编码成%2B,即让加号正确传递的 URL 如下:
|
|
在W3C 标准中规定了查询字符串中保留了+作为空格的转义
在查询字符串中,加号保留为空格的简写符号。因此,真正的加号必须被编码。该方法用于使查询 URI 更容易在不允许空格的系统中传递。
同时W3C 的 HTML4 标准中也规定了application/x-www-form-urlencoded的编码规则:
- 键值被转义。空格字符替换为
+,然后保留字符按RFC1738的 2.2 节所述转义:非字母数字字符替换为%HH,一个百分号和两个十六进制数字表示字符的 ASCII 码。换行符转义为“CR LF”对(即%0D%0A)。- 键值按照它们在文档中出现的顺序列出。键值之间通过
=分隔,键值对之间通过&分隔。
这也就是为什么前面提到的两个案例查询字符串中+都被认为是空格的转义,早在 1996 年就成为推荐标准,也是大多讨论中提到的“历史原因”,
大多语言和框架都有提供这种为不同部分采用不同编码的方式,如 Go 的标准库net/url就有PathEscape和QueryEscape来分别对路径和查询字符串编码。
|
|
用哪种字符编码?
最初的RFC1738只是规定了字符要先按某种字符编码转义,具体是什么字符编码要靠 URI 提供信息,如果没有提供则无法可靠的被解析。
最开始只要处理 ASCII 字符,到后来出现非 ASCII 字符,比如我们的 GB2312 字符集,不同的编码让通信变得困难,后来便出现了 Unicode 及其常用的一些字符编码如 UTF-8、UTF-16。
最新的RFC3986标准建议先按 UTF-8 转换,但此前的 URI 并不受该标准影响。
如 HTTP 的请求头Content-type中可以使用charset指定字符编码:
|
|
如何正确编码与解码
了解了 URL 的编码规则后,我们提供的 URL 各部分需要按标准编码,解码时也是对应不同部分按标准解码,保证数据的可靠传输。
- 注意对 URL 的不同部分的保留集做不同的编码处理,根据要编码的对象选择合适的方式,而不是直接对整个 URL 用一套编码。
- 把空格编码为
%20,加号+编码为%2B会更安全,因为他们适用于 URL 的各个部分
- 把空格编码为
- 注意 W3C 标准的查询字符串与
application/x-www-form-urlencoded是将空格编码为+,对应的解码也需要遵循该标准。 - 注意编码和解码时使用统一的字符编码。
思考:对已编码的 URL 解码后,是否能重新正确编码?
http://example.com/a%2Fb%3F1+2
使用 HTML 的 form 表单
在通过 HTML form 可以提交 GET 和 POST 请求,请求的数据都会先被 URL 编码后才发送,要注意表单提交的 GET 查询字符串和application/x-www-form-urlencoded格式传递的空格会被编码为+。
如提交 GET 请求的表单:
|
|
可以在地址栏看到实际请求的数据已经被 URL 编码:

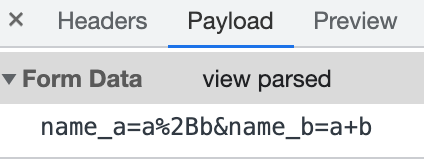
如提交 POST 请求的表单,请求头的Content-Type由 form 元素上的enctype属性指定,默认是application/x-www-form-urlencoded:
|
|
实际请求发送的也是被 URL 编码过的数据:
JavaScript
js 提供的函数:
| 函数 | 字符编码 | 不编码的字符 | 说明 |
|---|---|---|---|
| escape / unescape | UTF-16 | @ * _ + - . / |
- 已弃用 - 参数为字符串,不适用整个 URL - 使用 UTF-16 编码,码点大于 0x10000 则与 UTF-8 不一致了 - 不能编码 +,对于会把+解码为空格的服务端不能正确转义 |
| encodeURI / decodeURI | UTF-8 | 保留字符:; , / ? : @ & = + $非转义字符: - _ . ! ~ * ' ( )数字符号: # |
- 参数为完整 URL,不仅是查询字符串 - 适用百分号编码,不能编码 +,对于会把+解码为空格的服务端不能正确转义 |
| encodeURIComponent / decodeURIComponent | UTF-8 | - _ . ! ~ * ' ( ) |
- 参数为单个字符串,不适用整个 URL - 按百分号编码,如空格编码为 %20- 为了更严格遵循RFC3986,MDN上有推荐的安全使用方式 |
|
|
处理 URL 的查询字符串可以使用类URLSearchParams,会将空格编码为+
|
|
还可以使用一些第三方库处理查询字符串,如query-string,默认按百分号编码:
|
|
Python3
提供了两种编码方式quote和quote_plus,默认字符编码是 UTF-8
quote:百分号编码,适用于编码 URL 的路径quote_plus:百分号编码并指定空格编码为+,适用于编码查询参数
|
|
分别对应的解码方式unquote和unquote_plus
|
|
Go 中的编码
同样提供两种编码方式PathEscape和QueryEscape
|
|
分别对应的解码方式PathUnescape和QueryUnescape
|
|
扩展
- 字符集与字符编码:ASCII、Unicode、UTF-8
- 各种标准:RFC、W3C、ECMA、ISO
- HTTP 基础
参考
https://www.w3.org/TR/html401/interact/forms.html#h-17.13.4.1
https://www.w3.org/Addressing/URL/uri-spec.html
https://en.wikipedia.org/wiki/Percent-encoding
https://developer.mozilla.org/zh-CN/docs/Glossary/percent-encoding
文章作者 赖东东
上次更新 2022-11-16